Rei Thesis - Part 1

Opening Thoughts
Alright listen up. This one isn’t for the Reitards because they already know what they hold. This is for those that know nothing about Rei. And for the Crypto x AI shillfluencers that for some god forsaken reason keep referring to this as a framework project, or worse, calling Core an LLM: You are missing the forest for the trees.
@ReiNetwork0x first and foremost should be viewed as an AI lab (think Anthropic, OpenAI) that has built a fundamentally different AI architecture called “Core,” explicitly designed to address critical limitations facing LLMs today.
I wont spend too much time in this piece going through every aspect of LLMs and Core. There are tons of resources out there to learn about each of these in depth that I will link to where I can.
Instead, my goal is to outline factors that drive my conviction behind $REI (with more to come in Parts 2 and 3):
- ◆Technical Edge: Rei is addressing limitations that today’s models face such as stateless memory, frozen post-training knowledge and hallucinations.
- ◆Early Tech-Maturity Upside: Rei has shipped three Core iterations in ~6 months with many more upgrades to come (a series of repricing catalysts); Whereas big-lab LLM scaling cycles are longer and costlier.
- ◆Differentiation Attracts Attention: Rei’s approach to scaling intelligence through a deliberately different architecture sets them apart, drawing attention.
- ◆Only Liquid Pure-Play Exposure: Rei’s token is currently the only liquid public market exposure to an AI lab directly, without the dilution of a broader tech stack, which in turn draws attention and capital.
- ◆Crypto-Native Distribution Edge: Rei’s Web 3 friendly product features (Hanabi, crypto data integrations) secure an early user base other labs ignore. (Builder-incentive mechanics to be covered in Part 2.)
And before you ask me "But why would a serious AI lab launch a token?” See below.

I. Current Limits of LLMs
For those unfamiliar with the “magic” behind LLMs and what their limitations are, @karpathy’s deep dive is an excellent starting point: https://x.com/karpathy/status/1887211193099825254 And for a more visual, intuitive understanding of transformers, check out 3blue1brown’s playlist on YouTube: https://youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&si=F5jYxjdYhTQY_4QM
Before diving into Rei’s technical edge, a quick look at the limits today’s LLM playbook is running into.
For years, the AI narrative has been dominated by the pursuit of scale in LLMs. And rightfully so. They are undoubtedly useful for many tasks, transforming how we interact with information and automate processes. In my opinion, even in their current state, their maximum utility has yet to be fully unlocked.
Where LLMs Struggle
Despite their impressive capabilities, LLMs possess characteristics that impose constraints on near-term economic impact and potential ceilings for achieving true, general intelligence:
- ◆Amnesiac Savants (Stateless Memory): LLMs lack persistent memory. Each interaction is largely a fresh start. They can generate coherent text, but they don't truly evolve their understanding or build upon past conversations in a persistent way. Imagine having a brilliant conversation with someone, only for them to forget everything you just discussed the moment you start a new topic.
- ◆Lack of Genuine Learning (Frozen Weights): Unlike a human, LLMs cannot learn or adapt from continuous interaction. Every conversation, every problem solved, is largely a discrete event. They don't evolve or get intrinsically "smarter" over time through experience, preventing them from growing into a true "employee" from a mere tool.
- ◆Hallucinations: When faced with uncertainty or gaps in their knowledge, LLMs don't say "I don't know." Instead, they invent plausible, yet fabricated, information. This isn't a bug that can be easily patched; it's a fundamental characteristic of their probabilistic nature. In applications like finance or medicine, this becomes a critical vulnerability.
Note: These three ceilings (persistent memory, learning, and hallucination) are exactly where Rei’s Core diverges.
The Scaling Playbook
Over the past few years, most frontier labs have leaned on three main levers to push model quality forward:
- ◆More Compute: Bigger GPU/TPU clusters, longer training runs and heavier test-time FLOPs per query.
- ◆More Parameters: Ever-larger model sizes to capture more patterns.
- ◆More Data: Fresh web scrapes, licensed corpora, synthetic tokens.
Scaling these levers in combination with post-training optimization techniques like reinforcement learning have led to “emergent” capabilities in models like chain-of-thought. At the time of writing this, Open AI announced that an experimental general reasoning model of theirs earned Gold on the International Math Olympiad by solving 5/6 problems using language alone. There was little information about the techniques they used to achieve these results (I have a ton of questions), but the announcement is undoubtedly impressive.
However, training compute for frontier models has risen roughly 4-5× per year since 2019, so each flagship ends up sucking down an order-of-magnitude more GPUs, with matching surges in data-cleaning overhead and inference bills. Meanwhile, two stubborn facts remain:
- ◆The three ceilings I mentioned earlier (persistent memory, learning, and hallucination) barely budge.
- ◆Diminishing returns to scale: as @tobyordoxford shows in “The Scaling Paradox”, cutting test loss in half needs a million-fold more compute. https://www.tobyord.com/writing/the-scaling-paradox
These scaling techniques are likely to still yield some more surprises, but the cost curve is steepening and the unresolved flaws are harder to ignore.
Where Do We Go From Here
Over the last 2 quarters, sentiment around LLMs has felt more bifurcated than it has in the past.
Team Hype continues to look at these models through rose-tinted glasses: “iT’s SO ovER for [insert white collar job here]” every time a lab drops a new model. Team Skeptic asks questions: If LLMs are so smart, where is the measurable productivity jump? Where are the layoffs? Do the labs fear a capped upside on usefulness and so they explore other, easier wins like waifu Grok? (See @GoodAlexander’s doom thesis)
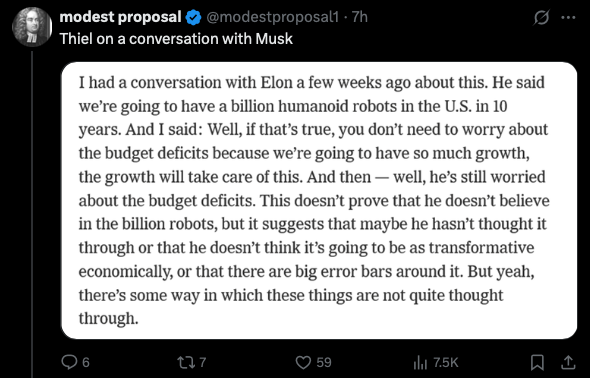
@dwarkesh_sp recently nailed a core issue (which btw is a gap that Core tackles):
https://x.com/vitrupo/status/1942591808149807463
Maybe it’s a matter of giving the technology time to permeate the economy. And maybe announcements like Open AI’s Gold IMO achievement ignite optimism in skeptics. Regardless, I don’t think it’s unreasonable to say that we should be exploring ways to scale AI through new architectures. @fchollet doesn’t (20:00 mark): https://x.com/ycombinator/status/1940772773951164607
II. Rei Network's Core: An Architectural Answer to LLM’s Challenges
If you haven’t already, I recommend reading through the following pieces on Rei:
Rei’s Central Thesis and Vision: Chasing AI’s Holy Grail https://x.com/ReiNetwork0x/status/1904942519198036050
Core ELI5 Edition: https://x.com/ReiNetwork0x/status/1944819976566935757
All the other items in @0xreitern’s thread: https://x.com/0xreitern/status/1934695925274038446
As noted earlier, memory, learning, and hallucination remain largely untouched. This is exactly where Rei’s Core comes in.
What is Core
Core isn’t a “better LLM.” It’s what the team calls a multimodal synthetic-brain architecture designed to solve for the flaws of the LLM approach. Instead of stretching one giant LLM ever wider, Core weaves together three main components:
- ◆Bowtie: Memory management and concept formation
- ◆Model Orchestrator: Dynamically routes tasks across specialist models
- ◆Reasoning Cluster: Executes complex reasoning tasks
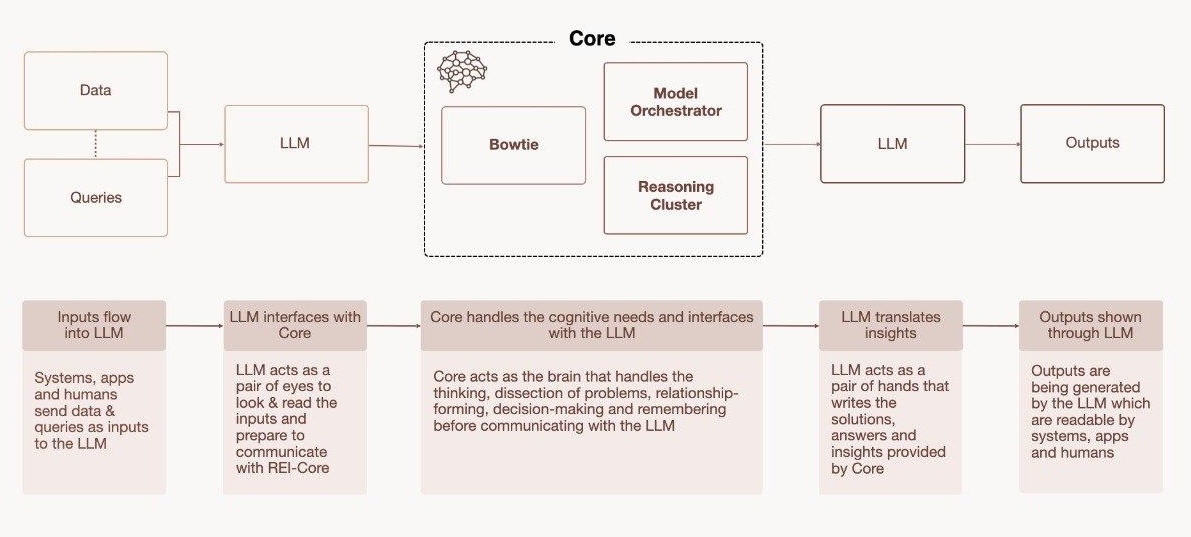
Core v0.2 high-level architecture - Note: v0.3 adds additional components inside the “Core” boundary. Those new components are omitted here for clarity.
In this architecture, the LLM’s role is heavily restricted to behaving like an interpreter for both the user inputs and Core outputs: It parses human prompts into Core’s internal format. It then verbalizes Core’s answer back to you.
We're not going to dive into every component of Core here. For a deeper explanation, the Rei documentation is your friend. Instead, what I want to do is focus on three key breakthroughs enabled by this architecture:
- ◆Persistent memory & conceptual understanding
- ◆Inference-time learning
- ◆Grounded generation (reduced hallucinations)
Breakthrough 1: Persistent Memory & Conceptual Understanding
Remember how we talked about LLMs being "amnesiac savants", brilliant but forgetful, unable to build on past interactions? Bowtie (Core’s memory system) directly tackles this.
Bowtie is an intrinsic memory layer, deeply embedded within Core’s internal state so things like retrieval, reasoning, and learning all run on this same circuitry.
How it Works:
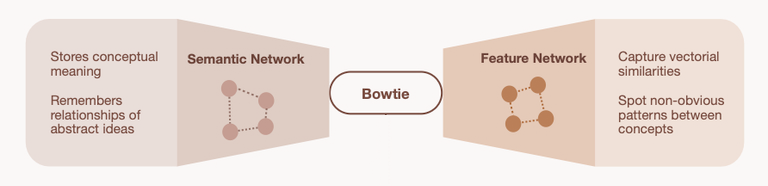
When raw data hits Bowtie (text, images, etc.), it isn’t just stored. The data is transformed through three components:
- ◆Semantic relationships: Bowtie cleans/strips unnecessary text and extracts explicit entities, attributes, and links.
- ◆Concept distillation: Those patterns are compressed into “concept” nodes with types, initial confidence scores, and relationship edges.
- ◆Vector features / similarity: In parallel it generates abstract feature vectors so new input can mix with similar past memories and surface non-obvious connections.
New or updated concepts are woven into the existing graph (merging with related nodes or forming fresh ones) so the Reasoning Cluster can use them on the very next interaction.
Think of it less like a database and more like a living map that continuously matures. Instead of “looking up” isolated facts, Core uses Bowtie to reason over an ever-richer web of linked concepts.
Technical Edge:
- ◆Reasoning Beyond Pattern Matching: This memory system provides Core with a foundation to reason and adapt that is inherently difficult for LLMs to achieve within their current state.
- ◆No Context Window Fatigue: In an LLM, the context window is like having a short-term memory that constantly gets overwritten. With Bowtie, your Unit’s (instances of Core) understanding of ongoing interactions, preferences, and specific domain knowledge persists and deepens. I've had Units that I've conversed with for weeks, and there's no degradation in performance or understanding as the conversation continues. Even when shifting topics.
Breakthrough 2: Inference-time Learning (How Core Evolves)
Because Bowtie gives Core a structured memory, the system can now learn from usage.
LLMs cannot learn and adapt. They only improve through costly offline fine-tunes; once deployed, their weights freeze. Relinking the Dwarkesh video I shared earlier to ground us in why continuous learning matters: https://x.com/vitrupo/status/1942591808149807463
Core’s Inference-Time Learning changes this. Every prompt you send is treated as live training data. Units running on Core literally update their internal knowledge graph, reinforce useful reasoning paths and trim bad ones while the conversation is happening.
How it Works:

Dynamic learning characteristics:
- ◆Confidence Building: Concepts start weak and get stronger with successful use (partial → confident → expert)
- ◆Silent Learning: The system learns even without corrections (signals like engagement length, follow-up questions, task success)
- ◆Memory Layers: Knowledge flows through stages (short-term → working → long-term) and auto-organizes by importance
You should pause here and spend some time reading through the Rei team’s Inference Time Training Guide as there are many examples in here showing what this system is capable of.
Here's one on Pattern Reinforcement Through Inference:
You: "Analyze these customer complaints"
Unit: [Infers patterns A, B, and C by reasoning through conceptual relationships]
You: "Good catch on patterns A and C. B isn't relevant here"
Unit: [Strengthens inference pathways that led to A and C, weakens those that suggested B]
Result: The unit learns which reasoning approaches work for your specific context.
Technical Edge:
1.Immediate user value
- ◆Compounding intelligence: Each solved task strengthens the Unit’s future reasoning pathways, so performance curves up instead of plateauing
- ◆Personalization moat: The longer a user engages, the more the Unit tailors itself, raising switching costs for rivals.
2. Platform/operational leverage
- ◆Compute efficiency: Because only light-weight concept graphs mutate, Core avoids the GPU-hungry weight-updates other approaches would need. Meaning Rei can run thousands of simultaneously learning Units without GPU retrains.
3. Strategic second-order effects
- ◆I’ll dig into more detail on this in Part 2 or 3 of my thesis, but I’d just like to quickly highlight (if it wasn’t obvious) that this is inference-time learning at scale. And how only a well thought out architecture gets you to a point where you can achieve this. Couple this technical leverage with the crypto rails that Rei is already native to, and you have yourself a foundation to build the “Unit Economy.”
Breakthrough 3: Grounded Generation (Reduced Hallucinations)
Persistent memory (Breakthrough 1) plus real-time reinforcement of correct reasoning paths (Breakthrough 2) give Core a grounded internal state before the LLM ever verbalizes an answer. That’s why we can keep this brief: the same mechanisms already described are what drive substantially lower hallucination rates.
How it Reduces Hallucinations:
- ◆Specialized model orchestration: Instead of forcing everything through one general LLM, Core routes subtasks to specialists models, then combines their outputs.
- ◆Structured memory + reasoning: The Reasoning Cluster works over Bowtie’s concept graph (not a flat prompt), supplying grounded facts and relationships during synthesis.
- ◆LLM demoted to a text engine: By stripping “reasoning responsibilities” from the LLM, generation is a surface translation step rather than an improvisational one.
- ◆Transparent synthesis: The system can expose which models contributed to an answer and the path taken, reinforcing trust.
Result: Rei’s internal testing shows a “well over 70%” hallucination reduction on complex analytical tasks versus a single LLM baseline.
Technical Edge:
1.Immediate user value
- ◆Reliability: Fewer hallucinations means answers you can act on without having to continuously cross-check.
- ◆Explainability: Core can surface which specialist models and concept links supported a claim, so users know why an answer is correct.
- ◆Lower support & compliance cost: Accurate, auditable outputs reduce human QA, legal review, and post-hoc corrections.
2. Strategic second-order effects
- ◆Opens high-stakes verticals: Transparent synthesis pathways satisfy audit trails that banks, pharma, and gov agencies demand.
- ◆Brand trust: Reliable performance compounds reputation, attracting enterprise deals and data partnerships the platform can reuse elsewhere.
Putting it Together
These three breakthroughs enabled by Core’s architecture move us beyond the brute force scaling of LLMs towards a different path: A system with the foundation to become more adaptable and more integrated into real-world workflows.
Rei’s technical edge is exciting and is why I’m paying attention, but it isn’t the whole thesis. There are other interesting angles to this trade. Moving on.
III. Beyond Architecture: Why Rei’s Edge Goes Deeper
Early Tech-Maturity Upside
Scaling intelligence through an alternative approach gives Rei another edge: Core doesn’t follow the same scaling laws as monolithic LLMs, putting it on a different trajectory entirely.
In roughly six months, Rei has shipped three iterations of Core with many more lined up. Yes, @0xreisearch moves at an incredible pace, but that cadence also reflects an architecture built for iterative improvement and compounding returns. The leap from v0.2 to v0.3 enabled inference-time learning. What will v0.4 or v0.5 bring?
This aggressive yet deliberate release schedule delivers a steady stream of powerful repricing catalysts. Don’t just look at Core for what it is today. But for what it can be in 6 months from now.
Differentiation & Pure-Play Exposure Attract Attention and Capital
One of the reasons I longed Solana in 2023 was simple: in a market saturated with EVM chains offering slight variations on the same theme, Solana stood out. The team knew what they were optimizing for (speed) and what tradeoffs they were willing to accept. That level of clarity offered me a straightforward hedge against the dominant SCP narratives of the time.
Rei feels analogous. With every lab racing to build a better LLM, Rei is intentionally optimizing in a different direction. Just like Solana’s speed-first vision, Rei’s clear stance on what matters and what doesn’t (Read the team’s central thesis and vision here.) turns this into an obvious alternative bet: a hedge against the prevailing “bigger LLM” trade.
This differentiation matters because it draws attention, but more importantly, it attracts specialized flows. In an industry where incremental model-size upgrades dominate the headlines, genuinely new ideas become a powerful magnet: generating outsized interest and ultimately, capital.
The Flow Angle (Pure-Play, Liquid Exposure)
On top of differentiation, Rei offers something exceptionally rare: direct liquid-market exposure to an early-stage AI lab.
Think about it: if you wanted a pure AI bet today, your options are limited. OpenAI, Anthropic, DeepMind are all locked inside private valuations or diluted inside larger tech conglomerates. Rei, on the other hand, is immediately investable, liquid, and accessible.
Why does this matter? Institutional capital increasingly wants focused, uncomplicated bets on high-conviction theses. The Rei token uniquely satisfies that demand, creating a loop: differentiation draws initial attention, and pure-play exposure turns attention into sustained capital flows.
Crypto-Native Distribution Edge
As AI competition heats up, the battle shifts increasingly toward distribution. Technical advantages matter, but user adoption is critical.
Rei understands this and is tapping a distribution channel largely ignored by bigger AI labs: the Web3 community. While of course also focusing on expanding to broader audiences. Read more about their business model here.
They’re doing this by shipping features tailored specifically to crypto-native users: Crypto data integrations (Defillama, Birdeye, Nansen [in progress], etc.), dynamic chartsand specialized market prediction models like Hanabi.
An accelerated feedback loop: Token holders aren’t just passive users. They have direct incentives to share in Rei’s success. With token ownership, Early adopters actively engage in rapid feedback cycles, feature requests, and user-driven product iterations. This dynamic creates a grassroots adoption engine that traditional AI labs lack.
IV. Conclusion
Valuation
At the time of writing this, Rei sits at a market cap of $130M. For context, it ranks #29 among crypto AI projects on (https://www.coingecko.com/en/categories/artificial-intelligence). And when compared to the valuations of AI giants like OpenAI or Anthropic…
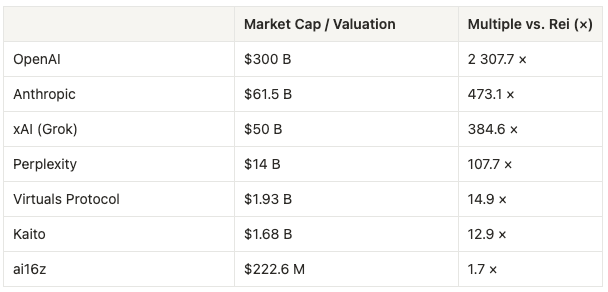
Speaking bluntly, it’s current valuation doesn’t make sense to me. It feels disconnected from the favorable risk-reward it presents. I’m not suggesting going all in, but even a modest allocation feels compelling given the sheer magnitude of the potential upside.
Looking Ahead
There’s still more to unpack. In Parts 2 and 3, I’ll dive deeper into things like:
- ◆Token Dynamics: How I see Rei strategically incentivizing API distribution through developer equity.
- ◆Rei’s Business Model: A more comprehensive breakdown of the revenue streams and growth strategies.
- ◆Narrative Dynamics
Beyond Core’s upcoming iterations, I’m especially looking forward to updates from the team on:
- ◆Academic Publications: Rei’s inference-time training guide hints at forthcoming academic research, which could further validate and amplify their technical credibility.
- ◆Cost Analysis: A detailed comparison of the economics of running Core versus traditional LLMs.
NFA. Thank you for your attention to this matter.
Affiliate Disclosures
- •The author and/or others the author advises do not currently hold, or plan to initiate, an investment position in target.
- •The author does not hold an affiliated position with the target such as employment, directorship, or consultancy.
- •The author is not being compensated in any form by target in relation to this research.
- •To the best of the author's knowledge, the information provided here contains no material, non-public information. The accuracy of the information is the responsibility of the reader.
7
0